Orika 使用不当导致的内存溢出问题
前言
最近突然收到了系统推送消息告警。打开一看,好家伙!直接 kafka 堆积超过了 100w 条数据,就差基础服务的人找上门来了。

经过简单的一系列排查,终于找到是代码中 Orika 工具使用不当导致内存增加、cpu 过高导致消费变慢。
下面记录下排查的思路
分析
出现消息堆积告警的时候,最开始的分析:
- 分片不均匀导致的消息堆积。因为出现告警的 topic 分片数是 8 个,服务实例只有 6 个。可能 某 个服务实例收到很多的消息,消费变慢,导致 kafka 消息堆积
- 流量突然增加
- 业务本身逻辑处理速度慢
- 内存增加导致 cpu 过高 消费变慢
解决过程
首先我们进行了服务实例的调整以及服务重启,但是这样并没有真正的解决问题。在服务重新运行的期间可以看见堆积量的减少,但是运行时间长后,堆积量又开始增加了。
其次通过观察业务的流量监控,也并没有发现流量的激增,是相对比较均匀的
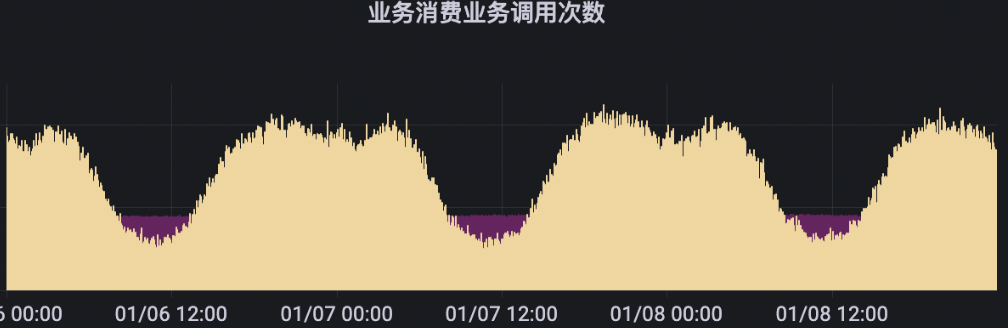
排查是否是业务执行太慢导致的。在 kafka 堆积问题出现前,业务的消费耗时都是正常的。也不是这个原因导致的堆积。
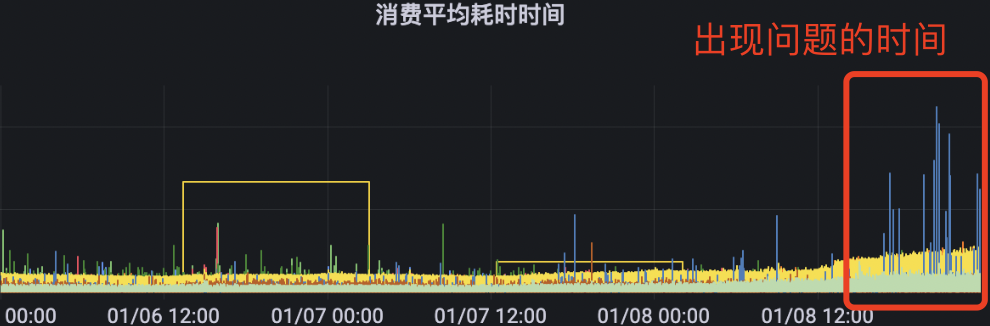
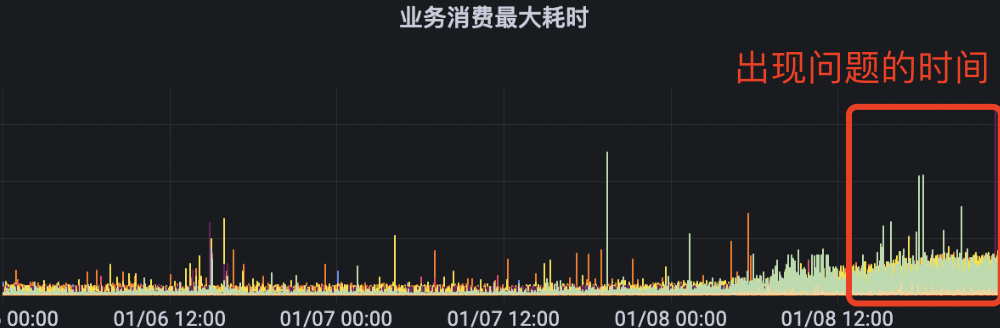
最后我们分析了实例的堆栈信息。找到对应内存爆满的实例,进入终端,通过 jmap 以及 mat 对实例的堆栈进行分析。
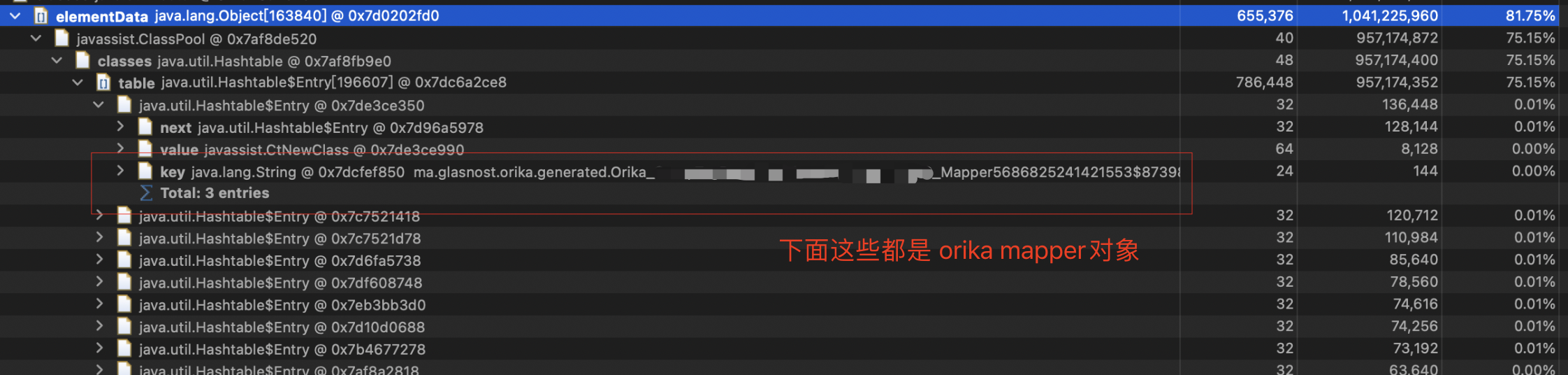 可以发现
可以发现 ma.glasnost.orika.generated.Orika_xxx_Mapper这个的对象占用了1G左右的内存,占了整个的81%。终于,我们找到了问题所在。
问题原因
下面是业务中使用 Orika 的一段代码
1 | |
解决方式
对应 register() 方法只用调用一次就行
1 | |
Orika 使用不当导致的内存溢出问题